

「データ実務家ミートアップ in 福岡」レポート
京部康男(データ横丁 編集部)[編]
データ活用コミュニティ「データ横丁」とマイナビTECH+の共催による「データ実務家ミートアップ in 福岡」が2026年4月10日に開催された。協賛はライトコード、後援には金融データ活用推進協会(FDUA)、データサイエンティスト協会、リテールAI協会、日本データマネジメントコンソーシアム(JDMC)が名を連ねた。本イベントは東京以外では初めての開催となり、地銀、小売、ゲームなど異業種のデータ実務家4名が、現場で得た知見や実践事例を紹介した。司会はバンダイナムコネクサスの吉村武氏が務め、当日は59名が参加し、会場の雰囲気を大いに盛り上げた。

「データが行員の行動を変える」──ふくおかフィナンシャルグループのNBA実装
「データや個人の中に蓄積されたナレッジというのは、出してみないと価値を生まないんです」──ふくおかフィナンシャルグループ(FFG)データソリューション部の稲垣源氏は、「”次の一手”を科学する」と題した講演の冒頭でこう語る。同氏は入社2年目のデータサイエンティストながら、現場感あふれる口調で、銀行の営業構造をデータで変えようとする取り組みを紹介した。
FFGは九州最大の広域展開型地域金融グループで、福岡銀行・熊本銀行・十八親和銀行・福岡中央銀行・みんなの銀行の5行を傘下に持つ。総資産32.2兆円(2025/03時点)は国家予算の4分の1規模に相当し、DX銘柄2025に地方銀行唯一の選出を受けている。そのデータ基盤はAWS上に構築され、グループ全体で多数のテーブルと膨大なデータ量を扱う。「セキュリティを強くしすぎると自由度が失われる。そのバランスを保ちながら、集めて繋げて使うという方法でやっています」と稲垣氏は話す。
同社が力を入れるのがNBA(Next Best Action)と呼ぶシステムだ。熟練行員と若手行員のスキル・ナレッジ格差を埋めることを主目的として、データ分析から導いた「次に行員が取るべきアクション」を日々配信する仕組みで、SFA(営業支援システム)のログイン直後の画面に表示される。現在約80件のシナリオが稼働している。
NBAのシナリオには大きく2種類ある。ひとつは外部データを活用したものだ。一例としては、ブルームバーグ社から取得した為替・金利・株価指標データを用い、顧客のボロール(取引)レートが一定額に達した際にフォローを促すという仕組みがある。「お客さまからすると、きちんと覚えてくれていると感じてもらえることから、リレーション強化に効いているといえます」と稲垣氏は言う。
もうひとつはAIを活用したシナリオだ。財務データと交渉履歴データをAIに渡し、たとえば「後継者未定」と交渉履歴に記録があり代表者年齢が72歳であれば、「事業承継ニーズあり」と判定してNBAを配信するというものだ。
また、稲垣氏が「一押しNBA」として紹介した事例では、長期不買の顧客の誕生日を機に支店長がお菓子を持参して訪問したところ、信頼関係が構築され、最終的に5億円の新規融資につながった。「お客さまの心の中にあるニーズを、アクションで引き出す。それがNBAの本質だと思っています」と稲垣氏は語った。
NBAのモニタリング・再分析を繰り返してターゲティング精度を高める取り組みも続けており、FC(ファイナンシャルコンサルタント)向けAIや法人AIレポートの開発も進めているという。
「テクノロジーで世界一のお買い物体験を」──トライアルカンパニーの横断DXとAIエージェント活用
600店舗超、売上高1兆3,000億円規模のディスカウントストアチェーン、トライアルカンパニー。そのCDO(最高デジタル責任者)を務める古賀輝幸氏は、1992年のアルバイト時代からプログラマーとして同社のPOSシステムを開発してきたという異色の経歴を持つ。
トライアルが掲げるビジョンは「テクノロジーと人の経験値で世界のリアルコマースを変える」。その中核を担うのが、2010年頃から自社開発を続けるデータ分析エンジン「e3SMART®」だ。RDBではなくLinuxコマンドベースで動作し、自社開発のSMARTコマンドによって小売業に特化した処理を実行する。BigQueryとの比較では処理速度18倍、コスト3分の1という数値を古賀氏は示した。
このe3SMART®を中心に、古賀氏が力を込めて語ったのが「バリューチェーンの横断DX」だ。258億件のID-POSデータを蓄積するMDリンクというプラットフォームを270社のメーカー・ベンダーに公開し、月間3.4万回のアクセスがある。「小売が欠品するなと言えば、卸は無駄な在庫を抱えるしかない。データで繋ぐことで、バリューチェーン全体の生産性を上げる」という考え方で、コラボレーションの深度に応じてカテゴリー設計→商品決定→在庫コントロール→価格決定権とメーカーに権限を委譲していく段階的な構造を取っている。
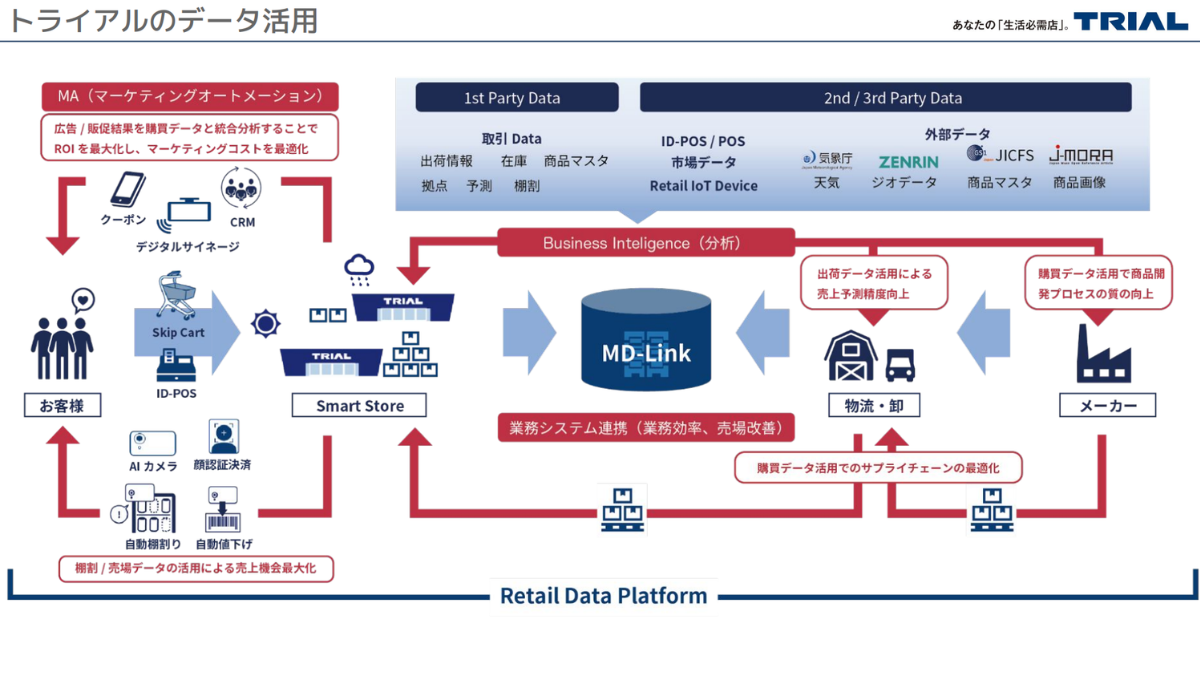
AIの活用については、e3SMART®にMCPを実装し、Claude(Anthropic)を通じて自然言語でデータ照会やMDリンクの棚割り分析ができる環境を構築しつつあるという。デモ動画では「6段棚の棚割りを作ってくれ」という指示に対し、AIが自動でデータを参照しながら対応する様子が披露された。「5段の棚割りは整備してあるが、ある店舗は6段だった。こういう現場のズレに対応できるのはすごく楽」と古賀氏。さらに先には、エージェンティックAIプラットフォーム「Teico」を業務アプリと連携させ、現場の従業員端末に「この棚の商品を処分して新しい商品を入れて」といった指示をAIが自動送信し、人間が実地確認して対応する──そんな「AIと従業員の共業」を描いている。「デジタル・データですべてを把握し、データで判断する新しい小売業になる。ソフトを入れることがDXではなく、ビジネスの根本が変わることがDXだと思っています」と古賀氏は語った。
「BigQueryのコストを効率的に削減」──ライトコードのAIエージェントとdbt活用の実際
ライトコードの新田隆氏(データ推進室 室長)は、バンダイナムコネクサス社の分析データパイプライン案件を題材に、BigQueryとdbt(データ変換ツール)を組み合わせたコスト削減の実践例を紹介した。
対象となったプロジェクトは、バンダイナムコネクサスの複数のモバイルゲームタイトルを横断する分析データパイプラインだ。タイトルごとにログテーブルのスキーマが異なるため、パイプラインを「スキーマ変換層」と「共通分析層」の2層構成にしている。スキーマ変換層では各タイトル固有のログを共通スキーマに変換し、共通分析層ではdbtのマクロ(共通クエリ)で全タイトル横断の分析を実行する構造だ。
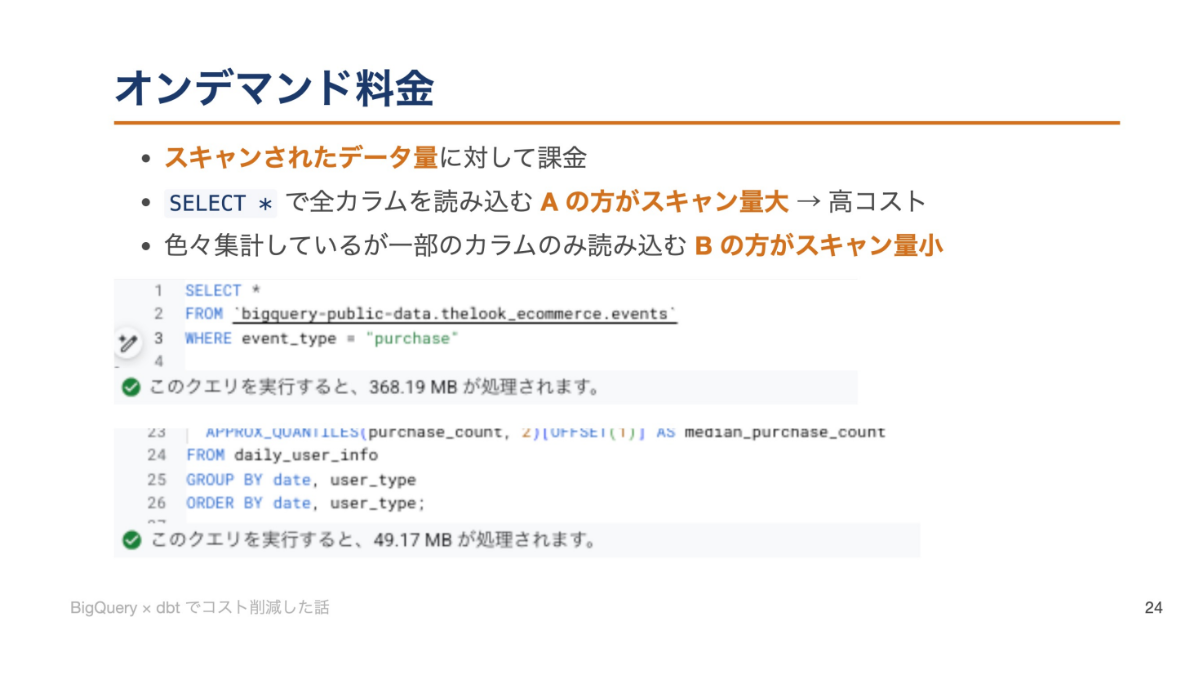
課題は、このスキーマ変換層のモデルがインクリメンタル(incremental=増分)更新に対応できていなかった点にある。毎回全期間のデータを集計し直す処理がBigQueryのコストを押し上げていた。dbtのインクリメンタル更新とは、毎回全期間を集計せず過去N日間など直近のデータのみを処理し、既存の過去データと組み合わせてテーブルを完成させる手法で、スキャン量を大幅に削減できる。
問題はタイトルごとにスキーマが異なるため、インクリメンタル化の対象モデルが多数あることだ。「このモデルをインクリメンタル化して」と単純にAIに指示するだけでは、パーティション列を正しく使ってくれなかったり、欠損や重複が発生したりと、うまくいかないケースが続出したという。
新田氏がとったアプローチは3段階だ。まず人間が1タイトルの1モデルを手作業でインクリメンタル化し、正しい実装例を作る(One-shot)。次にその例示を含む「インクリメンタルに対応するスキルを作成する」工程で、AIエージェントのSkillとして定義する。最後に、dev containerで実行環境を分離しサービスアカウントの権限借用で操作範囲を制限した上で、AIエージェントを完全自律モードで動作させる(素早く安全に動かす)。
この一連の工程により、スキーマ変換層の多数のモデルを効率よくインクリメンタル化でき、スムーズにコスト削減することに成功した。
後半では、BigQueryの課金体系の違いについても解説があった。BigQueryにはオンデマンド(スキャン量課金)と容量コンピューティング(Editions/予約スロット)の2つの課金モデルがある。オンデマンドはスキャンしたデータ量に対して課金されるため、単純なクエリでも巨大なスキャンが発生する可能性がある。容量コンピューティングはスロット(仮想CPU)使用量で課金されるため、計算量が多い複雑なクエリほど高コストになる。この2つのクエリの性質を示し、使い分けた事例を紹介し会場を引き込んだ。
「BI選定の答えは機能比較より先にある」──バンダイナムコネクサスの実践知
「BIにかかるコスト=ライセンスコスト?」という問いかけからセッションが始まった。バンダイナムコネクサスのデータテクノロジー部でアナリティクスエンジニアを務める永野啓介氏は、BIツールの選定と運用をめぐる現場の落とし穴を、自社の実体験に基づいて解説した。LookerやTableauを日常的に扱うエンジニアならではの実践的な知見が随所に光った。
同社のデータ基盤は、Amazon RDSやTreasure Data、App Store Connect APIなどのデータソースからembulkとTROCCOでデータを取り込み、BigQueryでraw data → data warehouse → data martと整備した上で、LookerとLooker StudioによるBI、JupyterとVertex AIによる分析に接続する構成だ。
永野氏が強調したのは、BI選定で見落とされがちな「運用コスト」の視点だ。ライセンス価格や機能比較、UI/UX、IdP(アイデンティティプロバイダー)連携といった観点で各ツールを比較する際、見えにくいのが「誰が運用して誰が保守するか」という問いだという。ロール設計によるライセンスコストの増減、ダッシュボードの公開範囲(部署単位か全社か外部公開か)、閲覧者数の増加ペース──こうした要素がトータルコストを左右する。クラウド型とセルフホスティング型の比較では「セルフホスティングは自由度と一緒に運用の仕事量も買う。クラウド型は箱の面倒が減るが統制の設計が要る」と整理した。
永野氏が挙げたのが4つの落とし穴だ。1)KPIが微妙に違うダッシュボードの乱立、2)「誰が何を変えたか」の追跡不能、3)影響範囲が読めずに触れられなくなること、4)「いつのまにかBIの中にETLができている」状態──これらがBI運用を辛くしているという。GUIで直感的に作れるBIツールは民主化を促す一方で、変更管理の難しさ・自動テストのしにくさ・似た指標の複製・依存関係の不透明化といった課題を抱えやすい。
これに対してバンダイナムコネクサスが実践したのがLookerのリポジトリをGitHubへ移管し、変更をコード管理する取り組みだ。コンソール画面だけで管理していた時期は「誰がいつ何を変えたか追えない。レビューもできず、変更理由も残らない」状態だったという。GitHubへの移管後はPRで差分が確認でき、チケットと紐づけて変更の経緯(Why)が追えるようになった。
さらに「変換処理をBIに寄せすぎる」ことへの警鐘も印象的だった。BI側で前処理(結合・整形・計算・フィルタ)を作り込みすぎると、ロジックがGUIに散在して属人化し、同じ変換の複製が増え、基盤側のスキーマ変更への追従が困難になる。「変換は基盤(DWH/モデル層)に寄せるほど運用が楽になる。BIは表現・探索・配布に徹するべき」というのが永野氏の結論だ。
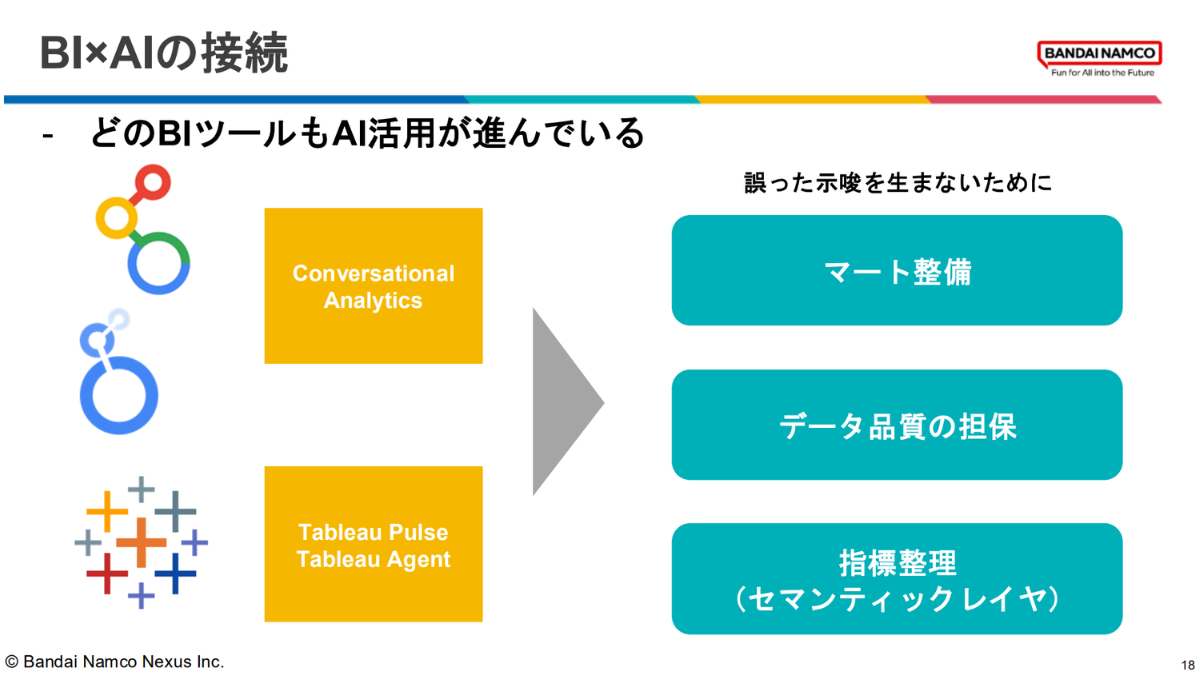
最後のテーマはBIとAIの接続だ。LookerのConversational Analytics、TableauのTableau PulseやTableau Agentといった機能が各ツールで整備されつつあるなか、「誤った示唆を生まないために必要なのはマート整備・データ品質の担保・指標整理(セマンティックレイヤ)の3つ」と永野氏は指摘する。Gemini in BigQueryによるメタデータ自動生成でカタログ整備を自動化し、Gemini in Lookerによる会話型分析やカスタム可視化生成でエンジニア以外もセルフサービス分析が可能になる環境を目指しているという。「BI選定は運用コストも意識、コード化する余地があると運用も楽、指標の整備はAI利活用にも繋がっていく」という3点がセッションのまとめとして示された。
まとめ──「分析」を「行動」に変える共通の問い
地銀がデータで営業行動を変える試み、小売がID-POSデータでバリューチェーンを再設計する構想、ゲーム企業がBIの運用課題をコード管理で解決した実践、そしてAIエージェントを活用してクラウドコストを効率的に削減した手法──業界も技術スタックも異なる登壇者たちが共通して語ったのは、「データを分析で終わらせず、行動や意思決定に繋げる」という問いだった。東京以外での初開催となった同ミートアップは、今後も各地での開催が期待される。


京部康男(きょうべやすお)
フリーランス編集者・ライター テクノロジーメディアおよび出版業界において、30年以上のキャリアを持つ編集者・ライター。ソフトウェア業界の採用支援を経て、1993年に翔泳社へ入社。経営企画部門にて株式公開(IPO)業務に従事した後、エディトリアル部門へ異動。 以来、IT開発者向けカンファレンスの立ち上げや、多数のIT専門誌・書籍の編集統括、デジタルメディア事業部長としての事業運営など、メディアビジネスの根幹を支える要職を歴任した。2010年代以降は、エンタープライズIT分野へと専門性を深化させ、ビジネスとテクノロジーが交差する領域でのコンテンツ制作に注力している。 現在は独立し、『EnterpriseZine』や『AIdiver』(共に翔泳社)といった有力ITメディアの中核メンバーとして活動。企業のAI実装戦略やデータガバナンスを主題とした深掘記事の執筆、グローバルなITベンダーによるイベントの講演コーディネート、さらには企業出版や行政情報誌の広報支援などを行う。