
望月茉梨藻 [著]
集まったのは30人、テーマは「考え方」
データ業界のテーマは幅広く、エンジニア、アナリスト、マネジメントなど、関わる人の職種やスキルもさまざまです。
データ横丁では、そうした多様な関心に応えるために、メンバー同士がテーマごとに集まり、ゆるやかに交流しあう勉強会を開いています。
勉強会のことを「〇〇通り」とネーミングし、専門や興味ごとに通りを歩きながら出会い語り合う―本通りからふと入った先に思わぬ出会いや気づきがある。
そんなイメージで運営されています。
9月11日の夜に開催されたのは、その「メタデータ通り」第2回。
会場には約30名が集まり、「考え方:メタデータとは何か、なぜ必要か」をテーマに議論が繰り広げられました。
堅そうな言葉が並びますが、会場の空気は和やか。
世話人兼モデレーターの安藤健一さんによる進行説明に続き、世話人の板谷健司さん・中村一星さんが紹介され、2時間の濃い学びの時間がスタートしました。
板谷さんが投げかけた「使いこなせる」データの条件
最初のインプットを担当してくださったのは、Quollio Technologiesの板谷健司さん。
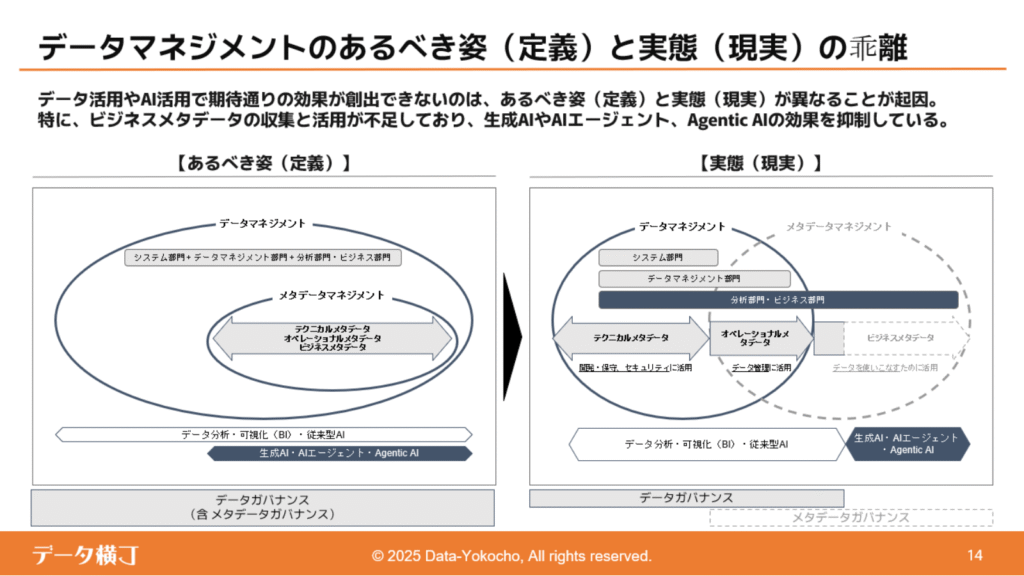
板谷さんは冒頭で「使える状態」と「使いこなせる状態」は違うのだと強調されました。
単に整ったデータを持っているだけでは不十分で、それを活かして業務や意思決定に結びつけてこそ価値が生まれる、という考え方です。

ここで披露されたのが「冷蔵庫と食材」の比喩です。
冷蔵庫に新鮮な野菜や肉、調味料が揃っていたとしても、それをどう調理するかを考え、食べる人に合わせた料理を作らなければ「ごちそう」にはなりません。
データも同じで、ただ保存されているだけでは意味を持ちません。
そのデータに“ラベル”を貼り、“文脈”を与え、“目的に合わせて使いこなす”ことによって初めて、組織にとっての成果や価値を生み出すのです。
続けて板谷さんは「セマンティック層」と「コンテキスト層」という二つの考え方を紹介しました。
セマンティック層とは「定義をそろえる」役割を担うもので、同じ言葉を誰もが同じ意味で理解できるようにします。
一方のコンテキスト層は「なぜそれを使うのか」「どんな前提や制約があるのか」といった背景情報を含みます。
たとえば「売上」という数値一つをとっても、計上基準や対象範囲が異なれば意味は大きく変わります。
AI活用が進めば進むほど、このコンテキスト層の整備が欠かせないのだと強調されました。
さらに「AI Readinessモデル」についても解説してくださいました。
AI活用の段階は1.0(支援)→2.0(補完)→3.0(自動化)と進化させていくべきものであり、いきなり高いレベルを目指すことの危険性を板谷さんは指摘します。
基盤が整わないまま拙速にAIを導入すると、効果が出るどころかコストや手間ばかりがかさみ「AI赤字」を招きかねない―言われてみれば当たり前、けれど一足飛びに活用しようとしてしまう。
皆さんにも心当たりがあるのではないでしょうか?
「データを単に“使う”のではなく“使いこなす”ために必要な条件」を具体的な比喩とモデルを通じて提示していただいたうえで、次のグループ討議へ入りました。
テーブルごとに違う景色、でも重なった言葉
会場は4つのテーブルに分かれ、イベントのメインコンテンツでもあるグループ討議へ。
テーマは「誰にどんなメタデータが必要か」。
各テーブルには模造紙とポストイットが用意され、参加者は自由に意見を書き出しながら、思い思いに議論を進めていきました。
模造紙が色とりどりに埋まっていく様子は、まるで料理の下ごしらえをしているかのようで、見ているだけでもワクワクする雰囲気です。
【テーブルディスカッションの様子を写した写真があれば入れたい】
暗黙知を見える化する
あるテーブルでキーワードになったのは「暗黙知」です。
日々の業務のなかで当たり前のように行われている判断やルールは、意外と文書化されていないものです。
そうした暗黙知をメタデータとして明示すれば、誰もが同じ基準で業務を進められるようになります。
さらに「アクティブ・メタデータ」という考え方も議論に上がりました。
利用ログやフィードバックを回収して、データそのものだけでなく、メタデータも改善していく循環をつくる。こうした仕組みがあれば、メタデータは一度作って終わりではなく、常に更新される「生きた情報」として機能していきます。
安心して使えるようにする
別のテーブルでは「安心感」が中心テーマになりました。
更新頻度や来歴(リネージ)といったシステム寄りの属性情報に加えて、利用者が「このデータを使っても大丈夫だ」と思えることが何より重要だという意見です。
法務や規程をメタデータに含めておくことで、「コンプライアンスに抵触しないか」「社外に共有してよいか」といった不安を減らせる。
データ利用の心理的ハードルを下げるためには、こうした“安心感の可視化”が必要だと強調されました。
利用者は社内だけじゃない
「ユーザーは社内の人間だけではない」という視点も共有されました。
たとえば、クライアントや監査を行う法務担当者も、データを利用する立場になり得ます。
利用者が社外まで広がると、当然ながら品質保証やセキュリティ、統制の重要性は増します。
内部向けのデータ管理で満足していたのでは不十分で、外部に示しても耐えうる水準で整備する必要があるのです。
定義は変わり続ける
さらに「定義は変わり続ける」という前提を持つべきだ、という指摘も出ました。
個人、部門、全社、社外へとスコープが広がるにつれて、必要とされる粒度や項目は変化します。
ある場面ではざっくりとした定義でよかったものが、別の場面ではより詳細な記述を求められるかもしれません。
AI活用を前提に考えると、ほとんどすべての情報を取り込む必要が出てくるケースもあり得ます。
こうした変化を想定してメタデータを設計することの重要性が、各テーブルで共通して語られました。
討議の内容はテーブルごとに多様で、焦点の置き方も違っていました。
しかし「暗黙知の見える化」「安心感」「利用者の拡大」「定義の変化」といったキーワードはどのグループからも繰り返し挙がり、視点が違っても最終的に重なる部分があることが明らかになりました。
実務に落とすときの“6つの小さなステップ”
グループ討議や板谷さんのインプットを振り返ると、メタデータの重要性を理解したうえでの「実際にどこから手をつければよいのか」という悩みも浮かび上がってきます。
理想を掲げるだけでは現場は動きません。
大きな仕組みを一度に構築するのではなく、小さなステップを積み重ねながら進めていくことが、実務に根づかせるためには不可欠です。
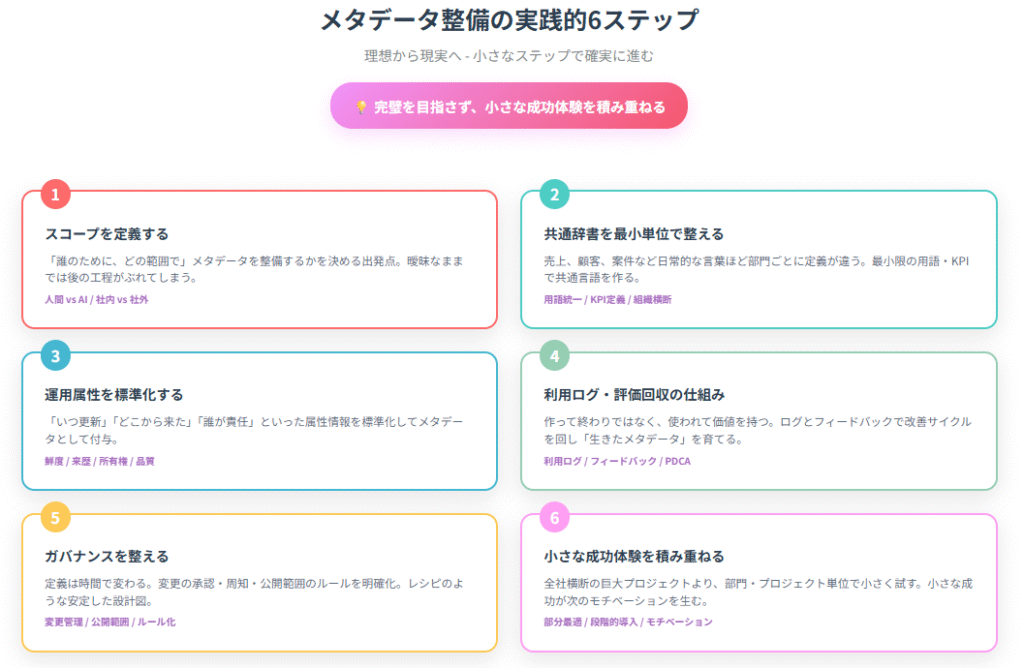
討議を通じて見えてきたのは、次の6つのステップです。
- スコープを定義する(人間かAIか、社内か社外か)
まずは「誰のために、どの範囲でメタデータを整備するのか」を決めることが出発点です。
人間が分析するのか、AIが利用するのか。
社内利用に限るのか、外部との共有も視野に入れるのか。
スコープを曖昧にしたままでは、後の工程がぶれてしまいます。 - 共通辞書を最小単位で整える(用語・KPI)
次に必要なのは「共通言語」を持つことです。
売上、顧客、案件―誰もが日常的に使う言葉ほど、実は部門ごとに定義が違っていたりします。
まずは最小限の用語やKPIを対象に共通辞書を整え、組織全体でズレをなくすことが第一歩です。 - 運用属性を標準化する(鮮度・来歴・所有権・品質など)
データには「いつ更新されたか」「どこから来たのか」「誰が責任を持つのか」といった属性情報が欠かせません。
これを標準化してメタデータとして付与することで、利用者は安心してデータを活用できます。 - 利用ログや評価を回収する仕組みをつくる
メタデータは作って終わりではなく、使われて初めて価値を持ちます。
利用ログを残したり、ユーザーからのフィードバックを回収する仕組みを設けることで、改善のサイクルが回り出します。
こうして「生きたメタデータ」が育っていきます。 - ガバナンスを整える(変更管理や公開範囲のルール化)
定義や属性は時間とともに変わります。
その変更を誰が承認し、どう周知するのか。
社内の誰まで公開するのか。
ルールを明確にすることで、混乱を防ぎます。
料理のレシピに「分量」「工程」「注意点」が書かれているように、ガバナンスはメタデータを安定して使い続けるための設計図です。 - 小さな成功体験を積み重ねる(完璧を目指さずPDCAで改善)
最後に大切なのは、完璧を求めすぎないことです。
最初から全社横断の巨大プロジェクトを立ち上げるのではなく、部門やプロジェクト単位で小さな取り組みを試し、成果を積み重ねることが現実的です。
小さな成功が次のモチベーションを生み、改善サイクルを回しやすくします。
メタデータ整備の実践的6ステップ
これらのステップは、いずれも現場で実践可能な小さなアクションに落とし込まれています。
大きな構想を描きつつも、「まずは一歩から」という姿勢で踏み出してみることが重要です。
次は「進め方」、宿題を持ってオンラインへ
「メタデータ通り」では、次回イベントのテーマを参加者の投票で決定していきます。
今回の内容を踏まえて投票してもらった結果、選ばれたのは「進め方:メタデータの拡充・推進手順」でした。
今回は、「メタデータがなぜ必要か」「どのように定義されるべきか」といった“考え方”に焦点が当てられていました。
しかし議論を進めるにつれて、「では実際にどう取り組みを進めるのか」という実務的な問いが次第に大きくなっていきました。
その延長線上で、次回は“進め方”についてご参加の皆さんと考えていければと思います。
ご参加の皆さんにお持ち帰りいただいた「宿題」はこちら:
- 自社やチームでの最小共通辞書を考えてくること
- アクティブ・メタデータをどのように回収できるかを検討してくること
【イベント風景の写真があれば入れたい】
各自の現場での課題を持ち寄り、コミュニティの場で共有することで、より実践的な知見が交わされる場を作ることを目指し、宿題ありのイベントとなっています。
「宿題を持って集合する」スタイルは、データ横丁らしい“共に作る場”を象徴していると言えるでしょう。
リアル会場での熱気をそのまま持ち越しながらも、地方在住やリモート勤務の方が、コミュニティに関われる機会を設けられればと考えています。
まとめ
「メタデータ」という言葉を聞くと、多くの人は専門的で難しいものを想像しがちです。
しかし今回のイベントでの議論を振り返ると、その本質は決して難解なものではありません。要は“データにラベルを貼り、安心して使えるようにする”ことです。
冷蔵庫に並んだ食材が、調理されてはじめてごちそうになるように、メタデータはデータを使いこなすために欠かせない存在なのです。
【集合写真があれば入れたい】
今回の討議では、暗黙知をどう明示化するか、安心感をどう担保するか、利用者をどこまで広げるか、定義の変化にどう対応するかといった、現場感のある視点が数多く共有されました。
それらを実務に落とし込むための6つのステップも浮かび上がり、理論と実践の橋渡しとなる道筋が見えてきました。
また、次回のテーマとして「進め方」が選ばれたことも象徴的です。
考え方を議論するだけでなく、それを現場でどのように展開し、組織として根づかせていくか。
より実践的な議論がかわされるであろう次回がとても楽しみです。
データ横丁は単なる勉強会ではなく、参加者一人ひとりが課題を持ち寄り、共に解決策を模索する“実験の場”です。
冷蔵庫をのぞくだけではなく、料理をつくり、食卓を囲み、味わう。
その繰り返しの中で、データもメタデータも血の通った存在へと育っていくのではないでしょうか。
望月 茉梨藻(もちづき まりも)
1990年生まれ。国際基督教大学卒。ジェンダーと社会構造を学んだのち、HRTech事業会社ビズリーチやスマートドライブにて業務設計・Salesforce運用を担当。業務データの整備や活用基盤の構築を通じて、メタデータや制度設計への関心を深める。現在はフリーランスとして、データに基づく業務改善や意思決定支援を行うほかライターとしても活動中。BizOps協会理事。
X:https://x.com/MarimonsterFun
note:https://note.com/marimoyoga

コメント